Llama3 & LangGraph
Local에서 LangGraph을 사용해 보자…!!!
Python
주피터에서 돌아가는 학예회 프로그램이 아닌 실무에서 사용할 수 있는 수준의 개발
메인 소스는 vectorstore, websearch 두 파트로 구성
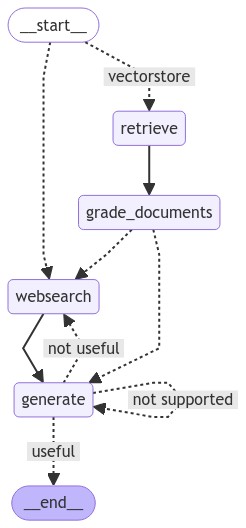
[LangGraph 플로우]
from dotenv import load_dotenv
from IPython.display import Image
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_community.chat_models import ChatOllama
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_nomic.embeddings import NomicEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import END, StateGraph, START
from pprint import pprint
from typing import List
from typing_extensions import TypedDict
local_llm = "llama3:latest"
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
retriever = None
retrieval_grader = None
rag_chain = None
hallucination_grader = None
answer_grader = None
question_router = None
web_search_tool = None
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question: str
generation: str
web_search: str
documents: List[str]
def init_retriever():
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=NomicEmbeddings(model="nomic-embed-text-v1.5", inference_mode="local"),
)
retriever = vectorstore.as_retriever()
return retriever
def make_retrieval_grader():
# JsonOutputParser retrieval_grader
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing relevance
of a retrieved document to a user question. If the document contains keywords related to the user question,
grade it as relevant. It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no premable or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n <|eot_id|><|start_header_id|>assistant<|end_header_id|>
""",
input_variables=["question", "document"],
)
llm = ChatOllama(model=local_llm, format="json", temperature=0)
retrieval_grader = prompt | llm | JsonOutputParser()
return retrieval_grader
def make_rag_chain():
# StrOutputParser rag_chain
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise <|eot_id|><|start_header_id|>user<|end_header_id|>
Question: {question}
Context: {context}
Answer: <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question", "document"],
)
llm = ChatOllama(model=local_llm, temperature=0)
rag_chain = prompt | llm | StrOutputParser()
return rag_chain
def make_hallucination_grader():
# JsonOutputParser hallucination_grader
prompt = PromptTemplate(
template=""" <|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing whether
an answer is grounded in / supported by a set of facts. Give a binary 'yes' or 'no' score to indicate
whether the answer is grounded in / supported by a set of facts. Provide the binary score as a JSON with a
single key 'score' and no preamble or explanation. <|eot_id|><|start_header_id|>user<|end_header_id|>
Here are the facts:
\n ------- \n
{documents}
\n ------- \n
Here is the answer: {generation} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "documents"],
)
llm = ChatOllama(model=local_llm, format="json", temperature=0)
hallucination_grader = prompt | llm | JsonOutputParser()
return hallucination_grader
def make_answer_grader():
# JsonOutputParser answer_grader
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing whether an
answer is useful to resolve a question. Give a binary score 'yes' or 'no' to indicate whether the answer is
useful to resolve a question. Provide the binary score as a JSON with a single key 'score' and no preamble or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|> Here is the answer:
\n ------- \n
{generation}
\n ------- \n
Here is the question: {question} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "question"],
)
llm = ChatOllama(model=local_llm, format="json", temperature=0)
answer_grader = prompt | llm | JsonOutputParser()
return answer_grader
def make_question_router():
# JsonOutputParser question_router
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are an expert at routing a
user question to a vectorstore or web search. Use the vectorstore for questions on LLM agents,
prompt engineering, and adversarial attacks. You do not need to be stringent with the keywords
in the question related to these topics. Otherwise, use web-search. Give a binary choice 'web_search'
or 'vectorstore' based on the question. Return the a JSON with a single key 'datasource' and
no premable or explanation. Question to route: {question} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question"],
)
llm = ChatOllama(model=local_llm, format="json", temperature=0)
question_router = prompt | llm | JsonOutputParser()
return question_router
def retrieve(state):
"""
Retrieve documents from vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer using RAG on retrieved documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question
If any document is not relevant, we will set a flag to run web search
Args:
state (dict): The current graph state
Returns:
state (dict): Filtered out irrelevant documents and updated web_search state
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score["score"]
# Document relevant
if grade.lower() == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
# Document not relevant
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
# We do not include the document in filtered_docs
# We set a flag to indicate that we want to run web search
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def web_search(state):
"""
Web search based based on the question
Args:
state (dict): The current graph state
Returns:
state (dict): Appended web results to documents
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
if documents is not None:
documents.append(web_results)
else:
documents = [web_results]
return {"documents": documents, "question": question}
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
print(question)
source = question_router.invoke({"question": question})
print(source)
print(source["datasource"])
if source["datasource"] == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "websearch"
elif source["datasource"] == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or add web search
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
web_search = state["web_search"]
state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---"
)
return "websearch"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score["score"]
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score["score"]
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
def main():
load_dotenv()
# 전역변수 초기화...
global retriever, retrieval_grader, rag_chain, hallucination_grader, answer_grader, question_router, web_search_tool
retriever = init_retriever()
retrieval_grader = make_retrieval_grader()
rag_chain = make_rag_chain()
hallucination_grader = make_hallucination_grader()
answer_grader = make_answer_grader()
question_router = make_question_router()
web_search_tool = TavilySearchResults(k=3)
# Build graph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("websearch", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrie11ve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_conditional_edges(
START,
route_question,
{
"websearch": "websearch",
"vectorstore": "retrieve",
},
)
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"websearch": "websearch",
"generate": "generate",
},
)
workflow.add_edge("websearch", "generate")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "websearch",
},
)
app = workflow.compile()
try:
graph_image = Image(app.get_graph(xray=True).draw_mermaid_png())
open('IntroOut.jpg', 'wb').write(graph_image.data)
except:
pass
# vectorstore
inputs = {"question": "What are the types of agent memory?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])
# websearch
# inputs = {"question": "Who are the Bears expected to draft first in the NFL draft?"}
# for output in app.stream(inputs):
# for key, value in output.items():
# pprint(f"Finished running: {key}:")
# pprint(value["generation"])
if __name__ == "__main__":
main()
pyproject.toml
[tool.poetry]
name = "ragollama"
version = "0.1.0"
description = ""
authors = ["snoopy_kr <snoopy_kr@yahoo.com>"]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.11"
langchain = "^0.2.6"
beautifulsoup4 = "^4.12.3"
chromadb = "^0.5.4"
gradio = "^4.38.1"
ollama = "^0.3.0"
langchain-community = "^0.2.7"
langgraph = "^0.1.4"
ipython = {extras = ["display"], version = "^8.26.0"}
langchain-upstage = "^0.1.7"
pdfplumber = "^0.11.1"
faiss-cpu = "^1.8.0.post1"
langchainhub = "^0.1.20"
langchain-anthropic = "^0.1.17"
langchain-groq = "^0.1.6"
langchain-nomic = "^0.1.2"
nomic = {extras = ["local"], version = "^3.0.45"}
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
.env
LANGCHAIN_TRACING_V2 = true
LANGCHAIN_ENDPOINT = https://api.smith.langchain.com
LANGCHAIN_API_KEY = <LANGCHAIN_API_KEY>
LANGCHAIN_PROJECT = <LANGCHAIN_PROJECT>
TAVILY_API_KEY = <TAVILY_API_KEY>
댓글남기기