LLM inference
LLM inference 분석
언어 모델링
-
Masked Language Modeling
텍스트 시퀀스에서 일부 토큰을 마스킹 처리하고, 이 마스크된 토큰을 예측하는 방식으로 작동된다.
시퀀스의 양방향에서 정보를 수집할 수 있어, 주변 토큰들의 전체적인 컨텍스트를 이해하는데 매우 유용하다.
BERT는 이 유형의 대표적인 예로, 다양한 자연어 처리 작업에서 탁월한 성능을 보임.
-
Causal Language Modeling
토큰 시퀀스에서 다음에 올 토큰을 예측하는 작업에 초점을 맞춤.
주어진 토큰의 왼쪽 정보만을 사용하여 다음 토큰을 예측, 시퀀스가 순차적으로 생성되는 상황에 적합하다.
GPT-2는 이 유형의 모델로서, 생성적 텍스트 작업에 자주 사용한다.
Autoregressive generation
최근 Large Language Models(LLM) 모델은 ‘Causal Language Modeling’을 통해 학습이며 ‘Autoregressive generation’이라는 기법을 사용하여 문장을 생성한다.
Autoregressive generation 방식은 모델이 문장을 생성할 때, 이미 생성한 단어나 토큰을 기반으로 다음 단어나 토큰을 예측, 생성하는 방법.
LLM은 주어진 텍스트 토큰 시퀀스를 입력으로 받아, 다음 토큰에 대한 확률 분포를 계산하며 이 확률 분포를 통해 모델은 가장 적절한 다음 토큰을 선택.
Autoregressive generation에서 LLM을 활용할 때 가장 중요한 점 중 하나는 다음 토큰을 어떻게 선택할 것인가?
선택 과정은 확률 분포를 기반으로 이루어지며, 가장 단순한 형태는 확률이 가장 높은 토큰을 직접 선택한다. 하지만 때때로 더 복잡한 방법을 사용하여 결과 분포에서 샘플링하기 전에 추가적인 변환을 적용할 수도 있다.
토큰 선택 과정은 특정 중지 조건이 충족될 때까지 반복적으로 수행되며 가장 흔한 중지 조건은 ‘End of Sentence’ (EOS) 토큰의 생성하며 문장 생성을 멈춥.
모델은 EOS 토큰을 언제 생성해야 하는지를 학습하며, 이 기준에 도달하지 않을 경우 미리 정의된 최대 길이에 이를 때까지 생성한다.
Decoding methods
-
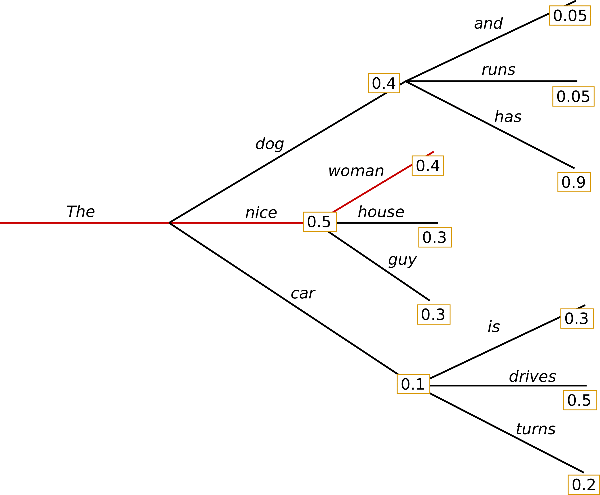
greedy search
가장 단순한 방법이며, 가장 높은 확률을 가진 단어를 다음 단어로 선택
-
contrastive search
A Contrastive Framework for Neural Text Generation에서 제시된 방법이며, 반복되지 않으면서도 일관성 있는 긴 출력물을 생성하는 데 뛰어난 결과를 보여줌
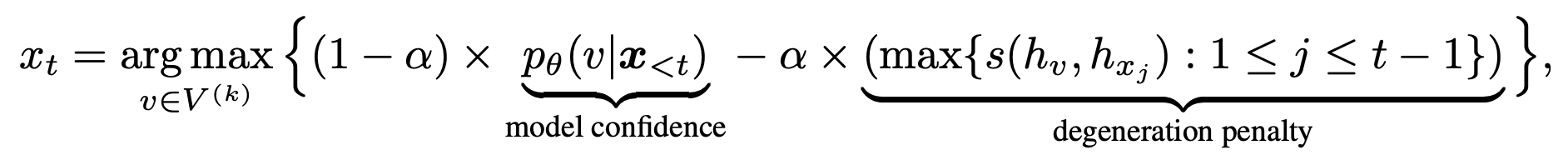
-
multinomial Sampling
모델에서 반환된 확률 분포를 기반으로 다음 단어를 무작위로 선택, 확률이 0이 아닌 모든 토큰이 선택될 가능성이 있으므로 반복적인 단어 선택이 감소됨.
-
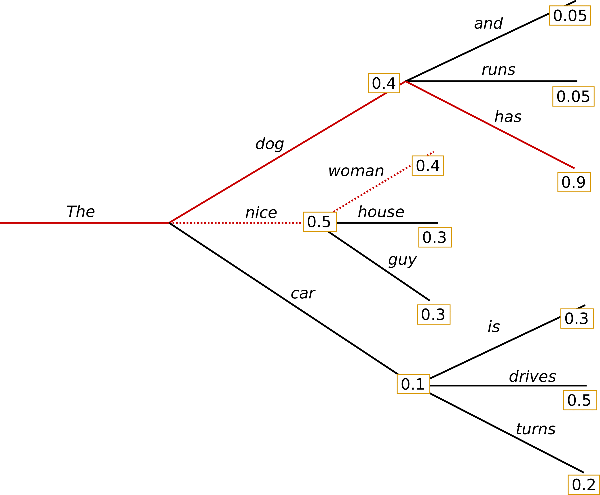
beam search
이전에 생성한 확률 분포를 몇 타임 스텝 동안 유지하면서 전체적으로 가장 높은 확률을 가진 시퀀스를 선택
- beam-search multinomial sampling
- diverse beam search decoding
- assisted decoding
자세한 내용은 Huggingface의 문서를 참고
참조
https://huggingface.co/blog/how-to-generate
https://huggingface.co/blog/introducing-csearch
https://huggingface.co/docs/transformers/v4.42.0/en/generation_strategies#multinomial-sampling
댓글남기기